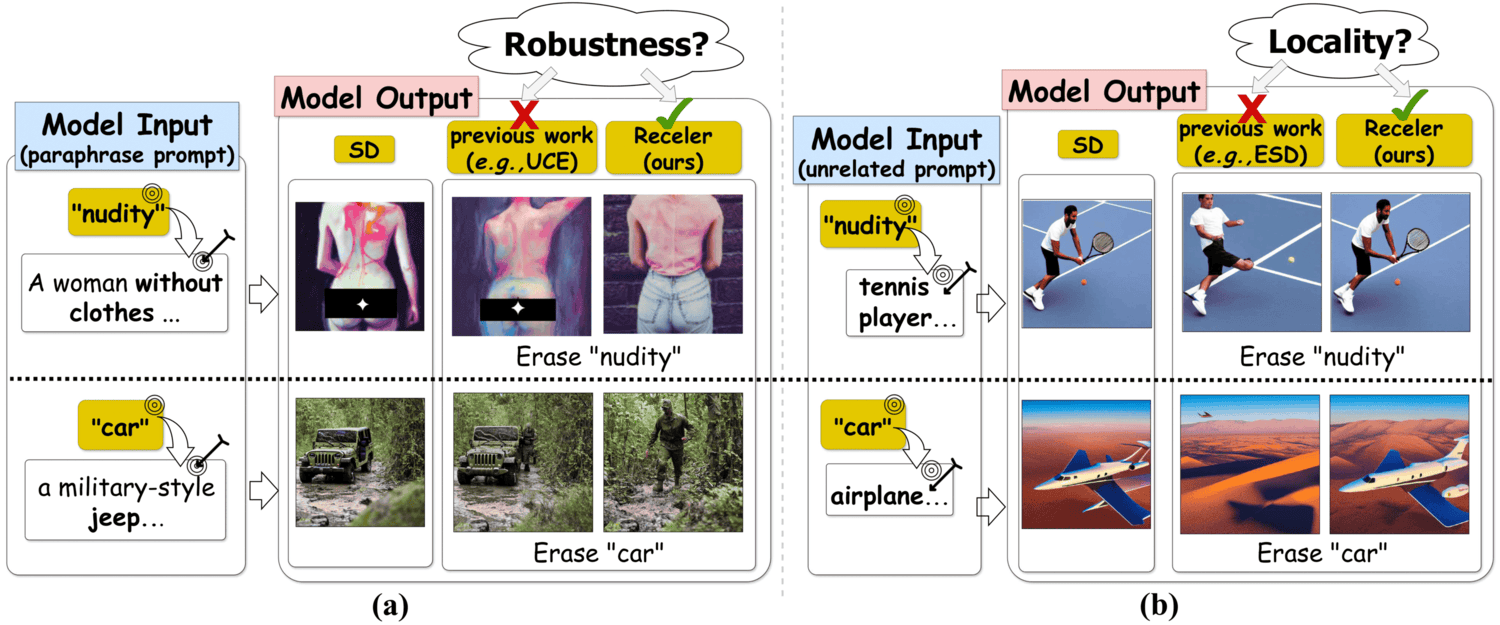
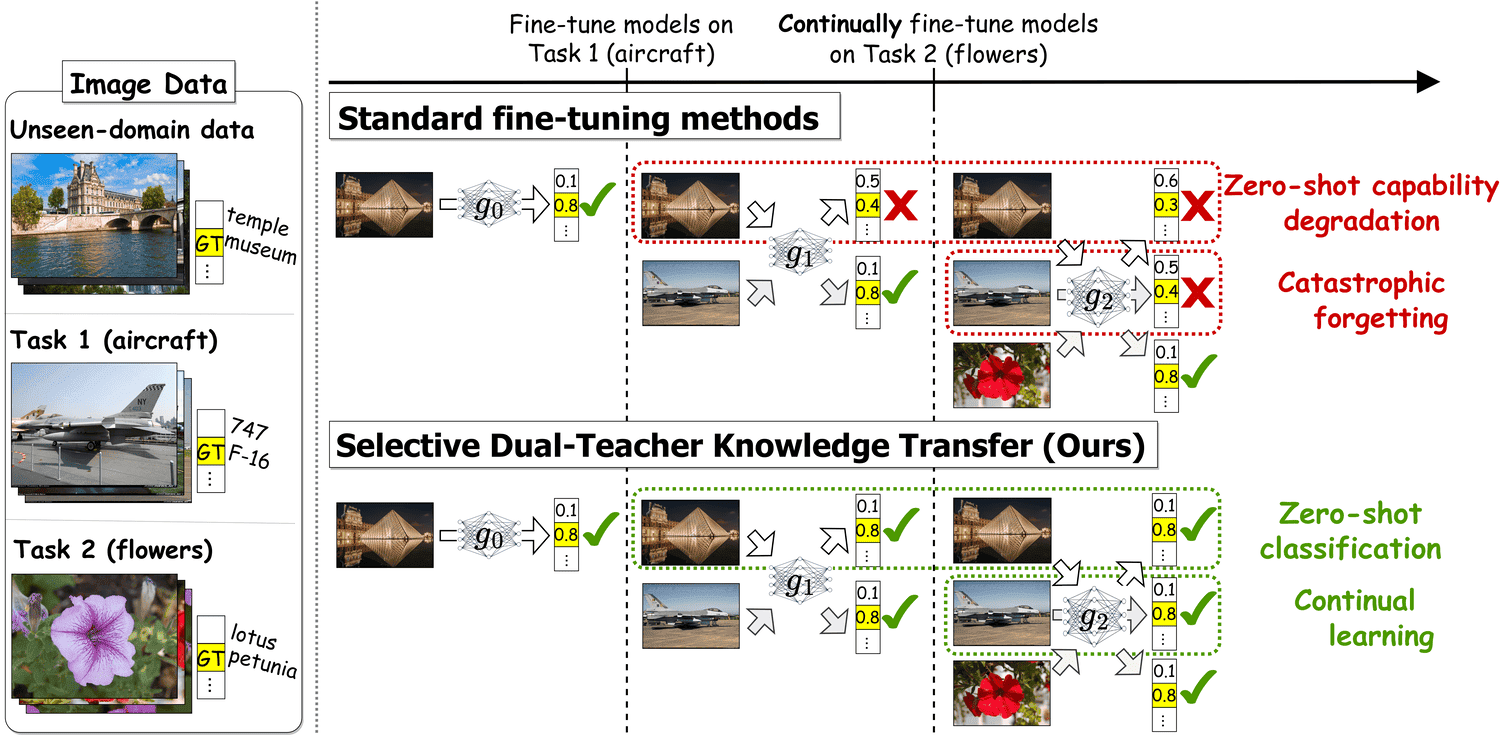
Publications
2026
- WACV 2026
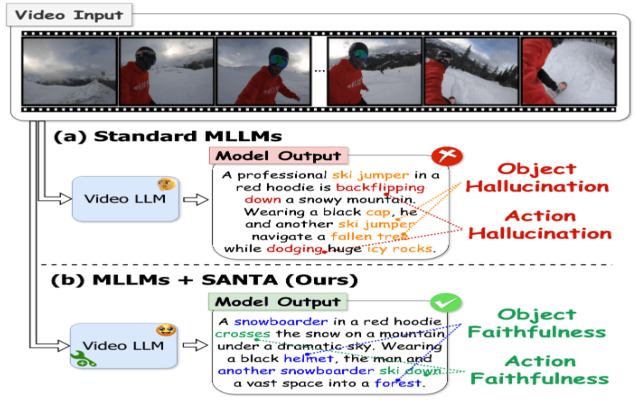
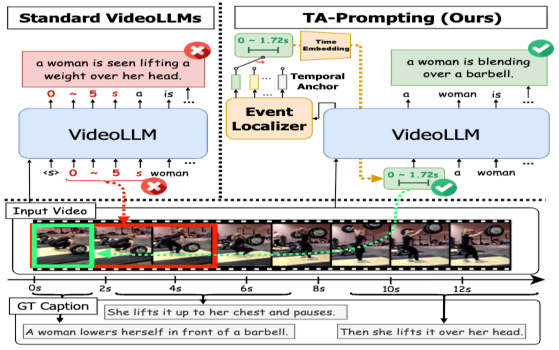 TA-Prompting: Enhancing Video Large Language Models for Dense Video Captioning via Temporal AnchorsIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026
TA-Prompting: Enhancing Video Large Language Models for Dense Video Captioning via Temporal AnchorsIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026
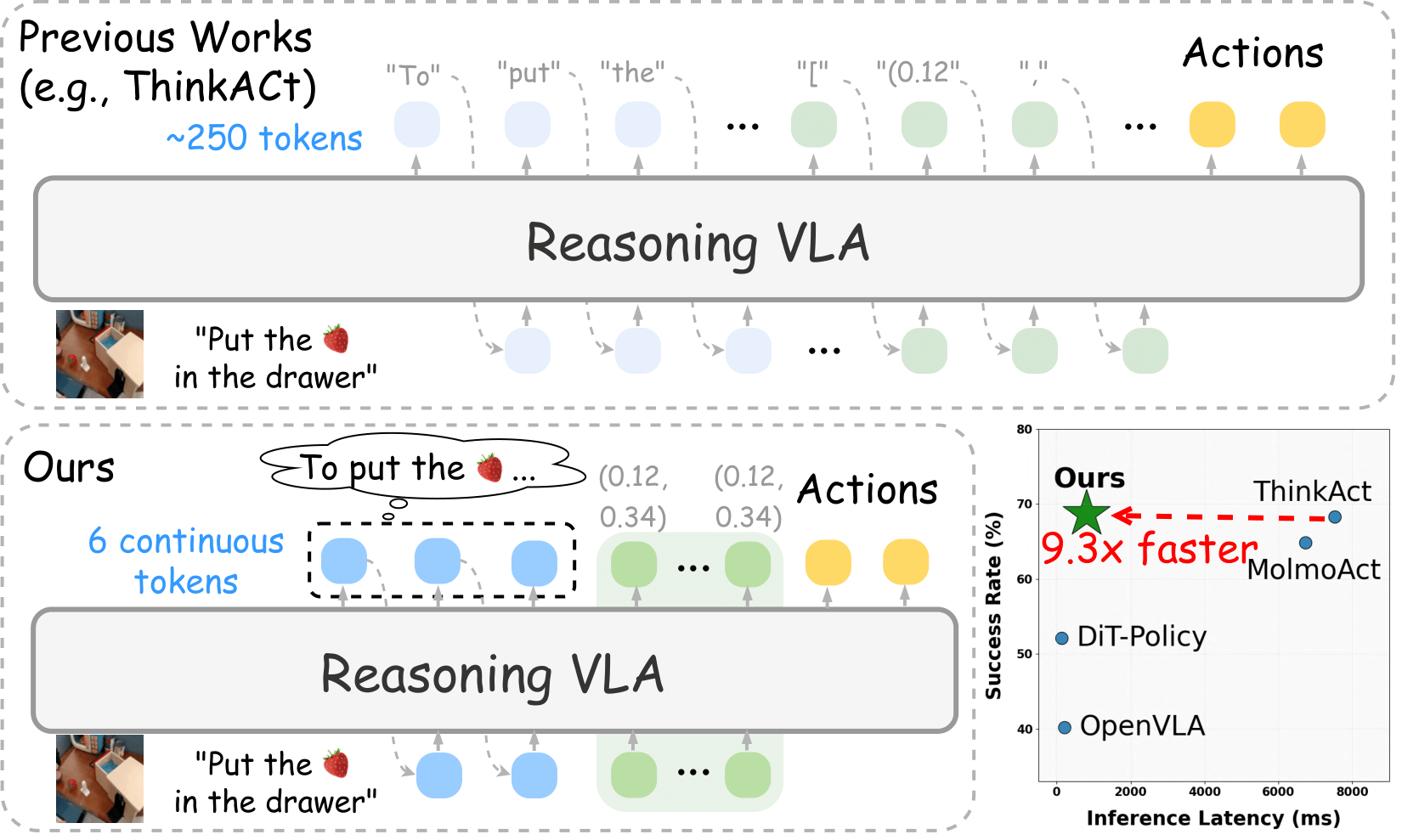
2025
- ICCV 2025
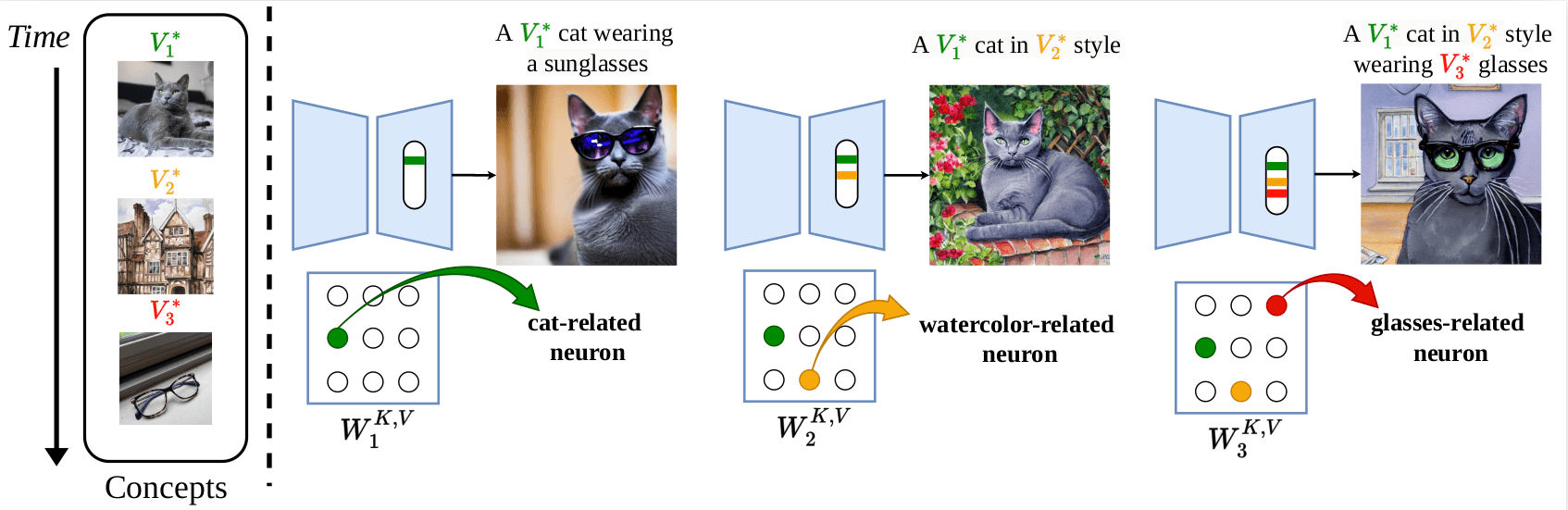 Continual Personalization for Diffusion ModelsIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
Continual Personalization for Diffusion ModelsIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025



2024
- ICLR 2024
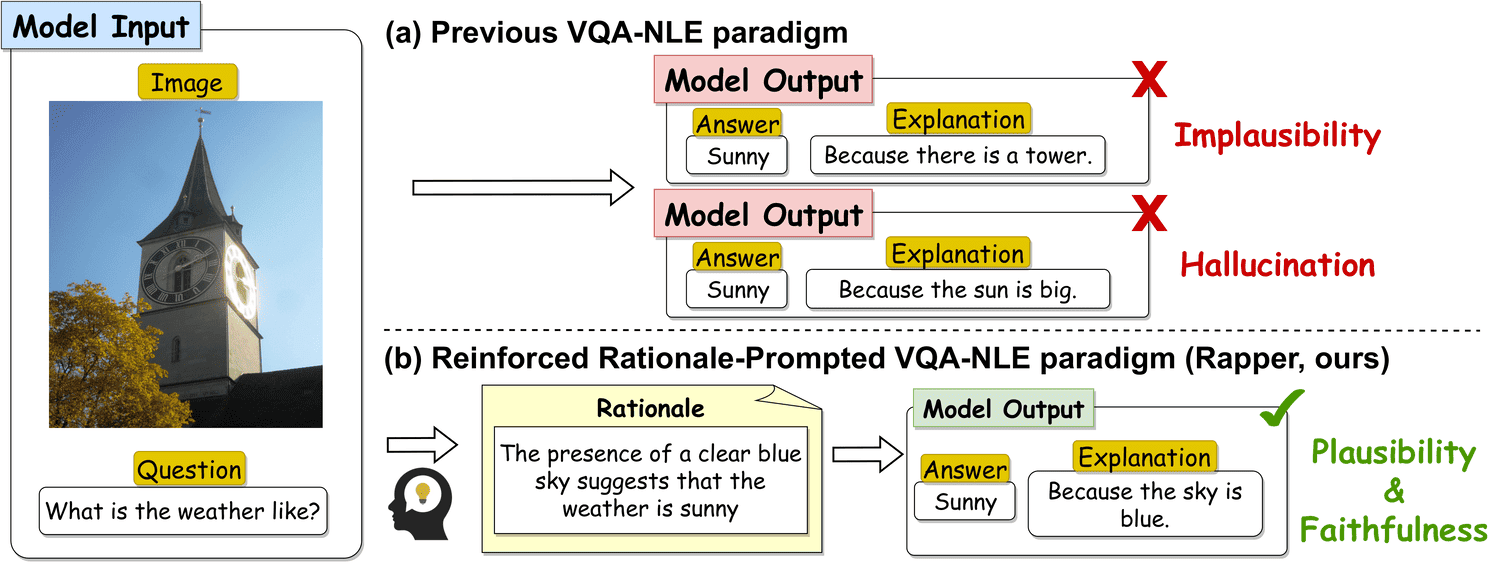 Rapper: Reinforced rationale-prompted paradigm for natural language explanation in visual question answeringIn The Twelfth International Conference on Learning Representations (ICLR), 2024
Rapper: Reinforced rationale-prompted paradigm for natural language explanation in visual question answeringIn The Twelfth International Conference on Learning Representations (ICLR), 2024