Chi-Pin Huang
Research Scientist

f11942097 [at] ntu.edu.tw
I am currently a Research Scientist at NVIDIA Research, working on vision-language-action models with a focus on reasoning and decision-making for Embodied Intelligence.
I received my Ph.D. from National Taiwan University (NTU) in January 2026 under the supervision of Prof. Yu-Chiang Frank Wang. Prior to my doctoral studies, I obtained my Bachelor’s degree in Computer Science and Information Engineering from NTU in 2022. I was also an Applied Scientist Intern at Microsoft, where I contributed to the development of deep learning models for Bing Maps.
My research focuses on Embodied AI, aiming to equip robots with the ability to reason about tasks and environments through world modeling and reasoning-enhanced vision-language-action models, enabling robust, environment-grounded decision-making and interaction in the physical world.
News
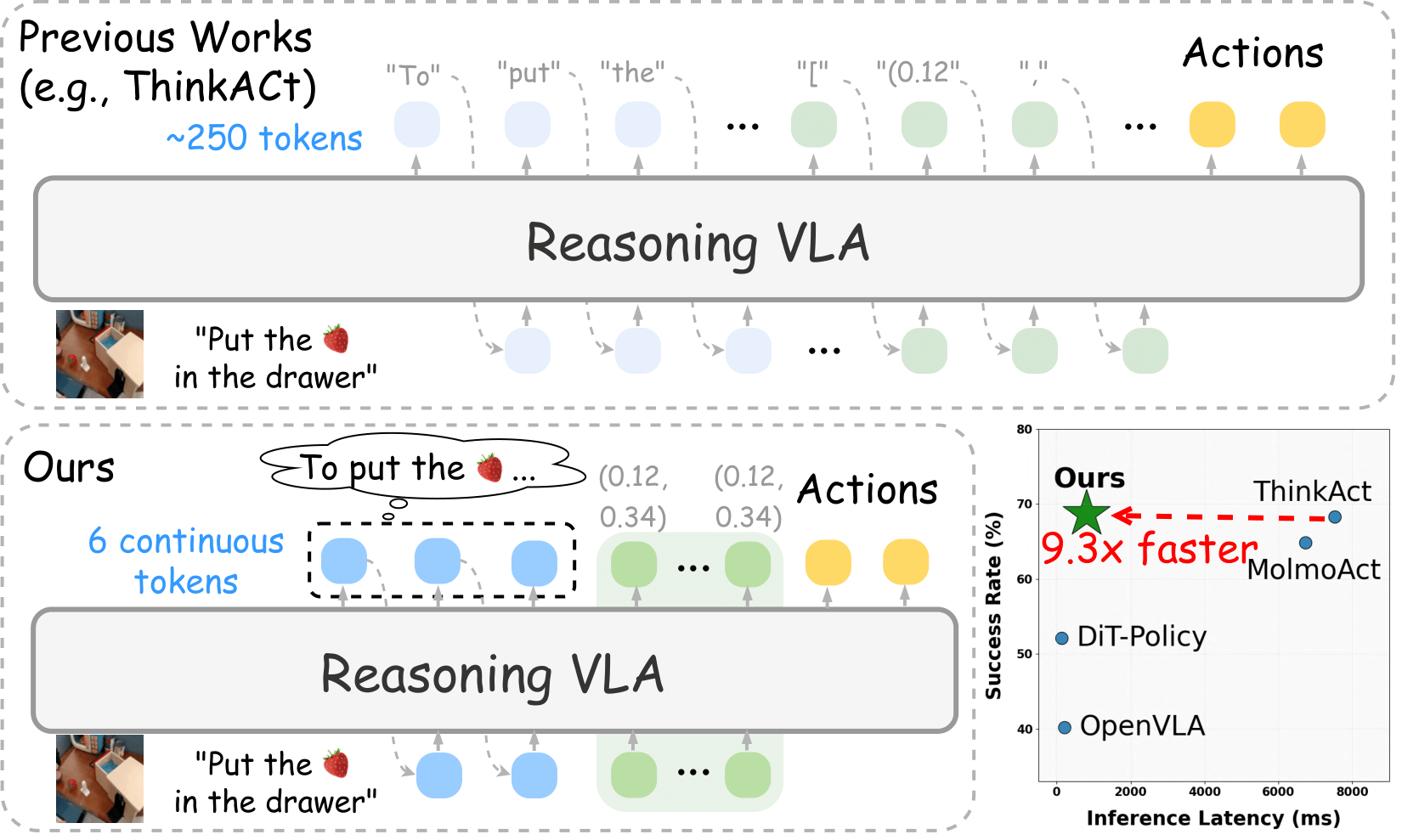
| Feb 20, 2026 | Our paper Fast-ThinkAct is accepted by CVPR 2026. |
|---|---|
| Jan 09, 2026 | Received my Ph.D. from National Taiwan University (NTU) and will be joining NVIDIA Research as a Research Scientist. |
| Dec 27, 2025 | Our papers “SANTA” and “TA-Prompting” are accepted by WACV 2026. |
| Sep 18, 2025 | Our paper “ThinkAct” is accepted by NeurIPS 2025. |
| Jun 26, 2025 | Our papers “CNS” and “MotionMatcher” are accepted by ICCV 2025. |
| Feb 27, 2025 | Our paper “VideoMage” is accepted by CVPR 2025. |
| Feb 03, 2025 | Join NVIDIA Research as a Research Intern. |
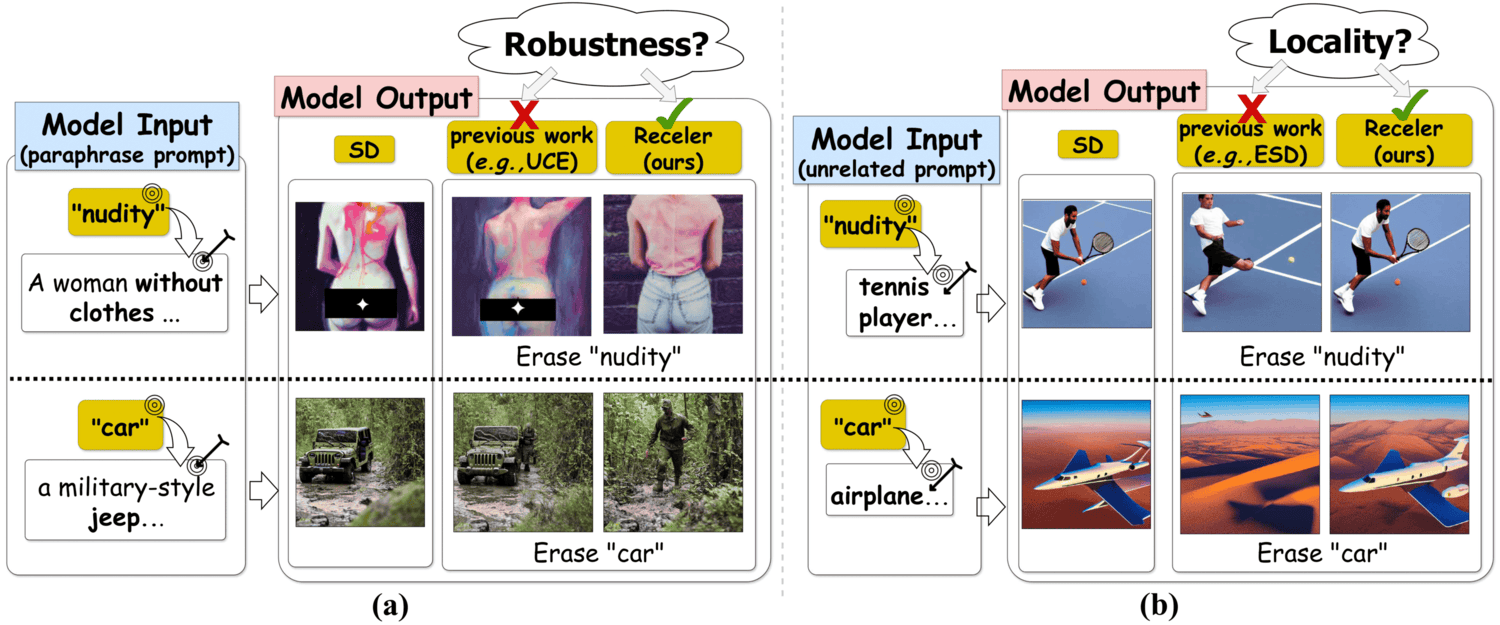
| Jul 02, 2024 | Our papers “Receler” and “Select and Distill” are accepted at ECCV 2024. |
| Jan 16, 2024 | Our paper “RAPPER” is accepted by ICLR 2024. |